OCR - Data Capture
Das Scannen von Papierdokumenten geschieht in mehreren Schritten: Zunächst wird mit einem Scanner ein digitales Abbild erzeugt, anschließend folgen die aufwendigeren Vorgänge, die Dokumentenklassifizierung und die Datenextraktion. Mittels leistungsfähiger OCR Software (Optical Character Recognition) werden die Inhalte automatisch erkannt.
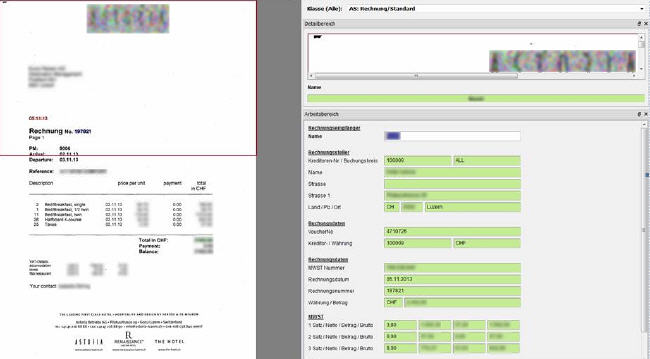
Wie aus Dokumenten Informationen werden: OCR Datenextraktion
Bei qualitativ guten gedruckten Texten gelingt dies mit einer hohen Erkennungsrate sehr zuverlässig, bei minderer Vorlagenqualität sowie bei Handschriften stoßen automatische Verfahren oft an ihre Grenzen. Der Abgleich mit vorhandenen Stammdaten (Personal, Kreditoren, Bestellungen etc.) verbessert die Resultate.
Indexdaten können automatisch erfasst und auf unterschiedlichste Weise validiert und geprüft werden. Nicht bzw. unzureichend erkannte Inhalte werden manuell ergänzt, respektive korrigiert. Die so gewonnenen Daten und Bilder (PDF, TIFF etc.) werden anschließend in den Workflow exportiert.
(C) 2019 - Tessi document solutions (Switzerland) GmbH - Alle Rechte vorbehalten